title: book2 – java核心API
toc: true
comments: true
categories:
abbrlink: 12e2449a
date: 2021-02-08 10:20:53
tags: Java
这里记录的是Java核心API的实践内容 !
[TOC]
(一)异常
1. 异常概述
1.1 运行时异常和检查时异常区别
运行时异常和检查时异常都继承自Throwable, 都是程序可以恢复的错误异常, 区别在于运行时异常会在程序运行时报错, 而检查时异常在运行前你编辑的时候就会报错
1.2 编程时常见异常
异常的体系:
Throwable
Error
Exception
- RuntimeException
1NullPointerException
2ArrayIndexOutOfBoundsException
3IndexOutOfBoundsException
4InputMisMatchException
5ArithmeticException
6ClassCastException
7NumberFormatException
- checkException
1ClassNotFoundException
2FileNotFoundException
3IOException
2. 异常处理
2.2 Java异常处理中try, catch, finally, throw, throws关键字作用
-
try块表示程序正常的业务执行代码。如果程序在执行try块的代码时出现了“非预期”情况,JVM将会生成一个异常对象,这个异常对象将会被后面相应的catch块捕获。
-
catch块表示一个异常捕获块。当程序执行try块引发异常时,这个异常对象将会被后面相应的catch块捕获。
-
throw用于手动地抛出异常对象。throw后面需要一个异常对象。
-
throws用于在方法签名中声明抛出一个或多个异常类,throws关键字后可以紧跟一个或多个异常类。
-
finally块代表异常处理流程中总会执行的代码块。
对于一个完整的异常处理流程而言,try块是必须的,try块后可以紧跟一个或多个catch块,最后还可以带一个finally块。
try块中可以抛出异常。
————————————————
版权声明:本文为CSDN博主「一位程序员小生的奋斗史」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/cwh615/article/details/52954474
3. 异常使用注意事项
3.1 当多个catch语句捕获异常且这些异常之间存在继承关系
- 捕获异常要遵循从大到小, 先父后子的顺序
4. 抛出异常
5. 自定义异常
(二)数据结构
1. 数据逻辑结构
1.1 数据的逻辑结构分哪几类, 并简要描述.
分为: 集合结构, 线性结构, 树结构还有图结构.
- 集合结构: 集合结构的集合中任何两个数据元素之间都没有逻辑关系,组织形式松散
- 线性结构: 线性结构指的是数据元素之间存在着“一对一”的线性关系的数据结构。
- 树结构(二叉树): 树状结构是一个或多个节点的有限集合。
- 图结构: 也叫网络结构, 网络结构是指通信系统的整体设计,它为网络硬件、软件、协议、存取控制和拓扑提供标准。
2. 数据存储结构
2.1 顺序存储结构和链式存储结构的优缺点.
内存开销: 链式存储结构更耗内存
数据操作: 顺序存储结构的优势在于数据的查询; 链式存结构的优势在于数据的增删
3. 线性结构
4. 查找
4.1 二分查找的使用范围
需要数据元素是有序的
(三)集合和泛型
1. 集合框架
1.1 hasNext()
- boolean hasNext()
返回 true如果迭代具有更多的元素。(换句话说,如果返回 true next()会返回一个元素而不是抛出一个例外。)
1.2 "未经检查或不安全"
如果遇到以下提示:
注: VectorTest.java使用了未经检查或不安全的操作。
注: 有关详细信息, 请使用 -Xlint:unchecked 重新编译。
在编译java源文件时,你使用的是jdk1.5或以上时,可能出现这个问题。(使用了未经检查或不安全的操作;请使用 -Xlint:unchecked 重新编译。)
原因是jdk1.5里的集合类的创建和jdk1.4里有些区别,主要是jdk1.5里增加了泛型,也就是说可以对集合里的数据进行检查。在jdk1.5以前,如果没有指定参数类型,则 JDK 1.5 编译器由于无法检查 给出的参数是否合乎要求,而报告 unchecked 警告,这并不影响运行。按照提示,编译是指定参数即可取消这样的警告。或者为其制定类型参数。
示例:
Vector v = new Vector();改为:
Vector<String> v = new Vector<String>();即可
2. Set接口
3. 迭代器(Iterator)
4. List接口
4.1 Set接口和List接口的区别
-
实现了Set接口的集合中的元素是无序不可重复的
-
List则是有序可重复的
5. 工具类
5.1 Collection和Collections的区别
- Collection: 通过这个接口实现了单值集合, 意义在于为各种具体的集合提供了最大化的操作方式
- Collections: 里面有很多静态方法, 此类不能实例化, 服务于Collection框架
6. 比较器
6.1 Comparable和Comparator的区别
- Comparable(内部比较器): 通过在集合元素所属的类中实现Comparable的CompareTo()方法进行比较
- Comparator(外部比较器): 通过对集合元素对象的某属性类别创建一个类, 使该类实现Comparator接口的Compare()方法来实现比较
比较器主要是用于List接口的实现集合中, 但是Comparable还能用于TreeSet, 这是因为TreeSet实现了SortedSet接口, 底层是二叉树实现的
7. Map接口
8. 自动拆箱和装箱
9. 泛型
9.1 使用泛型的好处
-
1,类型安全。 泛型的主要目标是提高 Java 程序的类型安全。通过知道使用泛型定义的变量的类型限制,编译器可以在一个高得多的程度上验证类型假设。没有泛型,这些假设就只存在于程序员的头脑中(或者如果幸运的话,还存在于代码注释中)。
-
2,消除强制类型转换。 泛型的一个附带好处是,消除源代码中的许多强制类型转换。这使得代码更加可读,并且减少了出错机会。
-
3,潜在的性能收益。 泛型为较大的优化带来可能。在泛型的初始实现中,编译器将强制类型转换(没有泛型的话,程序员会指定这些强制类型转换)插入生成的字节码中。但是更多类型信息可用于编译器这一事实,为未来版本的 JVM 的优化带来可能。由于泛型的实现方式,支持泛型(几乎)不需要 JVM 或类文件更改。所有工作都在编译器中完成,编译器生成类似于没有泛型(和强制类型转换)时所写的代码,只是更能确保类型安全而已。
Java语言引入泛型的好处是安全简单。泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,提高代码的重用率。
————————————————
版权声明:本文为CSDN博主「超锅_」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/chuang504321176/article/details/76739961
(四)IO和XML
1. File类
1.1 要使Java程序具有跨平台性,进行文件操作时
需注意不同的操作系统对文件路径的设定各有不同的规则,需要使用File类提供的一些静态属性去获得Java虚拟机所在的操作系统的分隔符相关信息,如PATH分隔符和路径分隔符
1.2 静态导入以及静态导入的优缺点
静态导入:从JDK1.5开始,增加了静态导入的特性,用来导入指定类的某个静态属性或方法,或全部静态属性或方法,静态导入使用import static语句
优点
让编写代码相对简单,可以少写几个单词
缺点
- 可能会出现导入冲突。例如,同时对Integer类和Long类执行了静态导入,引用MAX_VALUE属性将导致一个编译器错误,因为Integer类和Long类都有一个MAX_VALUE常量,编译器不知道使用哪个MAX_VALUE
- 因为毕竟没有完整写出静态成员所属的类名,程序的可读性有所降低
2. 字节流和字符流
3. 其他流
3.1 为什么需要使用缓冲流?
缓冲流是一种装饰器类,目的是让原字节流、字符流新增缓冲的功能。
如果只是无缓冲使用字符流、字节流,每次读、写操作都会交给
3.2 适配器模式和装配器模式
适配器模式
-
概念:将一个类的接口转换成客户希望的另外一个接口。Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
-
特点:主要应用于希望复用一些现存的类,但是接口又与复用环境要求不一致的情况。
-
分类:类适配器模式、对象的适配器模式、接口的适配器模式(差别较大)
-
实现思想:Target:用户期待的,最后需要的输出Adaptee:需要适配的类
(和装饰者模式初学时可能会弄混,这里要搞清,装饰者是对src的装饰,使用者毫无察觉到src已经被装饰了(使用者用法不变)。 这里对象适配以后,使用者的用法还是变的。
即,装饰者用法: setSrc->setSrc,对象适配器用法:setSrc->setAdapter.)
应用: SpringMVC中的HanlderMappingAdapter
————————————————
版权声明:本文为CSDN博主「cosmos_lee」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u012156116/article/details/80811260
装配器模式
-
概念:为已有的功能动态地添加更多功能的一种方式,就添加功能来说,比生成子类更灵活。
-
思想: component: 抽象构件角色:真实对象和装饰对象有相同的接口。
-
- concreteComponent: 需要装饰的对象(真实对象)
-
- Decorator:装饰角色,内含抽象组件的的引用、装饰者共有的方法
-
- ConcreteDecorator:具体装饰角色,负责给构建增加新的责任
-
开发中的使用场景:IO流的设计
-
优缺点:
优点:扩展对象功能,比继承灵活,不会导致类个数急剧增加
缺点:产生很多小对象。大量小对象占据内存,一定程度上影响性能; 多层装饰比较复杂。
————————————————
版权声明:本文为CSDN博主「cosmos_lee」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u012156116/article/details/80811260
4. XML概述
XML: eXtensible Markup Language ,可扩展标记语言
4.1 使用XML文档表示数据的优点及应用范围
优点
- XML文档的内容和结构完全分离
这个特性为XML的应用带来了很大的好处。基于这样的特点,企业系统可以轻松地实现内容管理和流程管理的彻底分离,例如系统架构师可以只关注流程运转中各环节的接口定义,而各部门则可以专注在内容发布和维护之上。
举例来说,微软公司的产品Biztalk正是利用了XML内容和结构分离的特点来实现内容和流程定义的分离。另外一个广泛的应用是XSL技术,由于XML文件的内容和结构分离,XSL才可以在不影响内容的情况下改变XML文件结构。
- 互操作性强
大多数纯文本的文件格式都具有这个优点。纯文本文件可以方便地穿越防火墙,在不同操作系统上的不同系统之间通信。而作为纯文本文件格式,XML同样具有这个优点。
- 规范统一
XML具有统一的标准语法,任何系统和产品所支持的XML文档,都具有统一的格式和语法。这样就使得XML具有了跨平台跨系统的特性。作为对比,同样作为文本语言,JavaScript的标准就远没有XML这样统一,以至于经常出现同一静态页面在不同的浏览器中产生不同的结果,而脚本程序员往往需要在程序的入口处费力地判断客户端所支持的脚本版本。
- 支持多种编码
相对于普通文本文档而言,XML文档本身包含了所使用编码的记录,这方便了多语言系统对数据的处理。
- 可扩展性
XML是一种可扩展的语言,可以根据XML的基本语法来进一步限定使用范围和文档格式,从而定义一种新的语言。例如:MathML(数学标记语言)、CML(化学标记语言)和TecML(技术数据标记语言),每种语言都用于其特定的环境。
————————————————
版权声明:本文为CSDN博主「每一步都要留下深脚印」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/csz_363874279qqcom/article/details/6261469
应用范围
- 数据交换
用XML在应用程序和公司之间作数据交换已不是什么秘密了,毫无疑问应被列为第一位。那么为什么XML在这个领域里的地位这么重要呢?原因就是 XML使用元素和属性来描述数据。在数据传送过程中,XML始终保留了诸如父/子关系这样的数据结构。几个应用程序可以共享和解析同一个XML文件,不必使用传统的字符串解析或拆解过程。相反,普通文件不对每个数据段做描述(除了在头文件中),也不保留数据关系结构。使用XML做数据交换可以使应用程序更具有弹性,因为可以用位置(与普通文件一样)或用元素名(从数据库)来存取XML数据。
- Web Service(web服务)
Web服务是最令人激动的革命之一,它让使用不同系统和不同编程语言的人们能够相互交流和分享数据。其基础在于Web服务器用XML在系统之间交换数据。交换数据通常用XML标记,能使协议取得规范一致,比如在简单对象处理协议(Simple Object Access Protocol,SOAP)平台上。SOAP可以在用不同编程语言构造的对象之间传递消息。这意味着一个C#对象能够与一个Java对象进行通讯。这种通讯甚至可以发生在运行于不同操作系统上的对象之间。DCOM, CORBA或Java RMI只能在紧密耦合的对象之间传递消息,SOAP则可在松耦合对象之间传递消息。
- 内容管理
XML只用元素和属性来描述数据,而不提供数据的显示方法。这样,XML就提供了一个优秀的方法来标记独立于平台和语言的内容。使用象XSLT 这样的语言能够轻易地将XML文件转换成各种格式文件,比如HTML, WML, PDF, flat file, EDI, 等等。XML具有的能够运行于不同系统平台之间和转换成不同格式目标文件的能力使得它成为内容管理应用系统中的优秀选择。
- Web集成
现在有越来越多的设备也支持XML了。使得Web开发商可以在个人电子助理和浏览器之间用XML来传递数据。为什么将XML文本直接送进这样的设备去呢?这样作的目的是让用户更多地自己掌握数据显示方式,更能体验到实践的快乐。常规的客户/服务(C/S)方式为了获得数据排序或更换显示格式,必须向服务器发出申请;而XML则可以直接处理数据,不必经过向服务器申请查询-返回结果这样的双向“旅程”,同时在设备也不需要配置数据库。甚至还可以对设备上的XML文件进行修改并将结果返回给服务器。
- 配置文件
许多应用都将配置数据存储在各种文件里,比如.INI文件。虽然这样的文件格式已经使用多年并一直很好用,但是XML还是以更为优秀的方式为应用程序标记配置数据。使用.NET里的类,如XmlDocument和XmlTextReader,将配置数据标记为XML格式,能使其更具可读性,并能方便地集成到应用系统中去。使用XML配置文件的应用程序能够方便地处理所需数据,不用象其他应用那样要经过重新编译才能修改和维护应用系统。
————————————————
版权声明:本文为CSDN博主「每一步都要留下深脚印」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/csz_363874279qqcom/article/details/6261469
4.2 应用范围:
- 数据存储
- 系统配置
- 数据交换
4.3 XML文档结构
1. 文档声明(可选)
2. DTD 约束 (可选)
3. 文档正文 (标签:不可以数字开头)
示例: <?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE team SYSTEM "team.dtd">
<team>
</team>XML元素命名规则
名称可以含字母、数字以及其他的字符
名称不能以数字或者标点符号开始
名称不能以字符 “xml”(或者 XML、Xml)开始
名称不能包含空格
标签名大小写敏感4.4 DTD: Document Type Definition
规范:元素、属性、元素间的关系
?: 被修饰的元素可以出现0次或1次
+: 被修饰的元素至少要出现1次
*: 被修饰的元素可以出现任意次
示例: <!ELEMENT team (coach,players)>
<!ELEMENT coach (name,sex)>
<!ELEMENT players (player+)>
<!ELEMENT player (name,age*,sex)>
<!ATTLIST player id CDATA #REQUIRED > //#REQUIRED:必须的,#IMPLIED:非必须的
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT sex (#PCDATA)>5. XML解析
5.1 解析XML文档有哪些技术,它们的区别是什么?
。DOM: 把整个xml文件读入内存进行解析
。SAX:一次读一部分,分段解析1.DOM生成和解析XML文档
为 XML 文档的已解析版本定义了一组接口。解析器读入整个文档,然后构建一个驻留内存的树结构,然后代码就可以使用 DOM
接口来操作这个树结构。优点:整个文档树在内存中,便于操作;支持删除、修改、重新排列等多种功能;缺点:将整个文档调入内存(包括无用的节点),浪费时间和空间;使用
场合:一旦解析了文档还需多次访问这些数据;硬件资源充足(内存、CPU)。
2.SAX生成和解析XML文档
为解决DOM的问题,出现了SAX。SAX
,事件驱动。当解析器发现元素开始、元素结束、文本、文档的开始或结束等时,发送事件,程序员编写响应这些事件的代码,保存数据。优点:不用事先调入整个文档,占用资
源少;SAX解析器代码比DOM解析器代码小,适于Applet,下载。缺点:不是持久的;事件过后,若没保存数据,那么数据就丢了;无状态性;从事件中只能得到文本,但不知该文
本属于哪个元素;使用场合:Applet;只需XML文档的少量内容,很少回头访问;机器内存少;
3.DOM4J生成和解析XML文档
DOM4J 是一个非常非常优秀的Java XML
API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件。如今你可以看到越来越多的 Java 软件都在使用 DOM4J 来读写
XML,特别值得一提的是连 Sun 的 JAXM 也在用 DOM4J。
4.JDOM生成和解析XML
为减少DOM、SAX的编码量,出现了JDOM;优点:20-80原则,极大减少了代码量。使用场合:要实现的功能简单,如解析、创建等,但在底层,JDOM还是使用SAX(最常用)、DOM、
Xanan文档。
XML文档定义有几种形式?它们之间有何本质区别?解析XML文档有哪几种方式?
答:a: 两种形式 dtd schema,b: 本质区别:schema本身是xml的,可以被XML解析器解析(这也是从DTD上发展schema的根本目的),c:有DOM,SAX,STAX等
DOM:处理大型文件时其性能下降的非常厉害。这个问题是由DOM的树结构所造成的,这种结构占用的内存较多,而且DOM必须在解析文件之前把整个文档装入内存,适合对XML的
随机访问
SAX:不现于DOM,SAX是事件驱动型的XML解析方式。它顺序读取XML文件,不需要一次全部装载整个文件。当遇到像文件开头,文档结束,或者标签开头与标签结束时,它会触发一个
事件,用户通过在其回调事件中写入处理代码来处理XML文件,适合对XML的顺序访问
————————————————
版权声明:本文为CSDN博主「涛之博」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_33624952/article/details/79368167
(五)反射机制
1. 反射引入
1.1 Java反射机制
- java反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取信息以及动态调用对象的方法的功能称为java语言的反射机制。
- 创建的每一个类都是对象,即类本身是java.lang.class类的实例对象,这个实力对象称为类对象,也就是Class对象。
- 在一个Java虚拟机中,一个类,只会有一个类对象存在。
————————————————
版权声明:本文为CSDN博主「江湖@小小白」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zhu_fangyuan/article/details/108711050
2. Class类
2.1 获取Class类有哪几种方法
常见有5种
- Class.forName()
Class c = Class.forName("java.lang.Object");- 类名.class
Class c = Car.class;- 包装类.TYPE
Class c = Integer.TYPE;- 对象名.getClass()
String name = "大力士";
Class c = name.getClass();- Class 类.getSuperClass()
Class c = String.class.getSuperClass();3. 获取类信息
3.1 使用反射机制创建对象有哪两种方法
- 通过Class类的newInstance()方法创建对象(使用对应类的无参构造方法创建对象)
public class TestNewInstance {
public static void main(String args[])
try {
Class c = Class.forName("Super");
//通过Class类的newInstance()方法创建对象
Super sup = (Super)e.newInstance();
System.out.println(sup.supPublic());
}catch (Exception e) {
e.printStackTrace();
}
}- 通过Constructor的newInstance(Object[] args)方法创建对象(使用对应类的有参构造方法创建对象)
import java.lang.reflect.*;
public class TestNewInstance {
public static void main(String args[]) {
try {
Class c = Class.forName("Super");
//返回一个指定参数列表(int, class, int.class)的Constructor对象
Constructor con = c.getDeclaredConstructor(new Class[]{int.class, int.class});
//通过Constructor的newInstance(Object[] args)方法创建对象,参数为对象列表
//参数列表对基本数据类型支持自动装箱、拆箱,所以也可以写成newInstance(21, 22)
Super sup = (Super)con.newInstance(new Object[]{21, 22});
System.out.println(sup.supPackage());
//返回一个无参的Constructor对象
Constructor con2 = c.getDeclaredConstructor();
//通过Constructor的newInstance()方法创建无参对象
Super sup2 = (Super)con2.newInstance();
System.out.println(sup2.supProtected());
}catch(Exception e) {
e.printStackTrace();
}
}
}4. 动态调用
5. 操作动态数据
5.1 Java如何实现动态数组的功能
Java在创建数组的时候需要指定数组的长度,且长度不可变,这就是静态数组,但是java.lang.reflect包下提供了一个Array类,这个类种包括一系列static方法,通过这些方法可以创建动态数组(长度可变),对数组进行赋值、取值操作
Array类提供的主要方法(均为静态方法)如下
- Object newInstance(Class componentType, int length)
创建一个具有指定元素类型和长度的新数组
- Object newInstance(Class componentType, int…dimensions)
创建一个具有指定元素类型和维度的多维数组
- void setXxx(Object array, int index, xxx var)
将指定数组对象中索引元素的值设置为指定的xxx类型的var值
- xxx getXxx(Object array, int index)
获取数组对象中指定索引元素的xxx类型的值
要动态添加数据必须要用到动态数组,动态数组中的各个元素类型也是一致的,不过这种类型已经是用一个非常大的类型来揽括—t类型,t类是java.lang包中的顶层超类。所有的类型都可以与t类型兼容,所以我们可以将任何t类型添加至属于t类型的数组中,能添加t类型的的集合有ArrayList、Vector及LinkedList,它们对数据的存放形式仿造于数组,属于集合类。
特点
特点一、容量扩充性
从内部实现机制来讲ArrayList和Vector都是使用的数组形式来存储的。当你向这两种类型中增加元素的时候,如果元素的数目超出了内部数组目前的长度它们都需要扩展内部数组的长度,Vector缺省情况下自动增长原来一倍的数组长度,ArrayList是原来的50%,所以最后你获得的这个集合所占的空间总是比你实际需要的要大。所以如果你要在集合中保存大量的数据那么使用Vector有一些优势,因为你可以通过设置集合的初始化大小来避免不必要的资源开销。
特点二、同步性
ArrayList,LinkedList是不同步的,而Vector是的。所以如果要求线程安全的话,可以使用ArrayList或LinkedList,可以节省为同步而耗费开销。但在多线程的情况下,有时候就不得不使用Vector了。当然,也可以通过一些办法包装ArrayList,LinkedList,使他们也达到同步,但效率可能会有所降低。
特点三、数据操作效率
ArrayList和Vector中,从指定的位置(用index)检索一个对象,或在集合的末尾插入、删除一个对象的时间是一样的,可表示为O(1)。但是,如果在集合的其他位置增加或移除元素那么花费的时间会呈线形增长:O(n-i),其中n代表集合中元素的个数,i代表元素增加或移除元素的索引位置。为什么会这样呢?以为在进行上述操作的时候集合中第i和第i个元素之后的所有元素都要执行(n-i)个对象的位移操作。
注意事项
-
如果只是查找特定位置的元素或只在集合的末端增加、移除元素,那么使用Vector或ArrayList都可以。如果是对其它指定位置的插入、删除操作,最好选择LinkedList
-
ArrayList和Vector是采用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,都允许直接序号索引元素,但是插入数据要设计到数组元素移动等内存操作,所以索引数据快插入数据慢,Vector由于使用了synchronized方法(线程安全)所以性能上比ArrayList要差,LinkedList使用双向链表实现存储,按序号索引数据需要进行向前或向后遍历,但是插入数据时只需要记录本项的前后项即可,所以插入数度较快。
-
ArrayList和Vector中,从指定的位置(用index)检索一个对象,或在集合的末尾插入、删除一个对象的时间是一样的,可表示为O(1)。但是,如果在集合的其他位置增加或移除元素那么花费的时间会呈线形增长:O(n-i),其中n代表集合中元素的个数,i代表元素增加或移除元素的索引位置。为什么会这样呢?以为在进行上述操作的时候集合中第i和第i个元素之后的所有元素都要执行(n-i)个对象的位移操作。
(六)多线程
1. 多线程概述
1.1 多线程的优势
-
在程序内部充分利用CPU资源。在操作系统中,通常将CPU资源分成若干时间片,然后将这些时间片分配给不同的线程使用。当执行单线程程序时,单线程可能会发生一些事件,使这个线程不能使用CPU资源,对于CPU而言,该程序处于不能使用CPU资源的状态。而当一个线程不能使用CPU资源时,其他线程仍可以申请使用CPU资源,使得程序继续运行。如果是多个CPU计算机,则多个CPU可以分别执行一个程序里的多个线程,程序的并发性得到进一步提升。
-
简化多任务程序结构。如果不采用多线程机制,那么要完成一个多任务的程序,则有两种解决方法。一种是采用多个进程,每个进程完成一个任务,多个进程共同完成程序的功能,当然这其中的缺点前面已经详细介绍过。另一种解决办法还是单线程,在程序中判断每项任务是否应该执行以及什么时候执行。这就让程序变得复杂,不易理解,而且程序内部不能实现多任务,执行速度慢。采用了多线程机制,可以让每个线程完成独立的任务,保持线程间通信,从而保证多任务程序功能的完成,也使程序结构更加清晰
-
方便处理异步请求。例如当用户访问服务器程序时,最简单的处理方法就是,服务器程序的监听线程为每个客户端连接建立一个线程进行处理,然后监听线程仍然负责监听来自客户端的请求。使用多线程机制,可以更好地处理监听客户端和处理请求之间的矛盾,方便异步请求的处理。
-
方便处理用户界面请求。如今所见即所得的用户界面程序,都会有一个独立的线程来扫描用户的界面操作事件。如果使用单线程处理用户界面事件,则需要通过循环来对随时发生的事件进行扫描,在循环的内部还需要执行其他的代码
2. 创建和使用线程
2.1 wait()、notify()、notifyAll()等方法介绍
在Object.java中,定义了wait(), notify()和notifyAll()等接口。wait()的作用是让当前线程进入等待状态,同时,wait()也会让当前线程释放它所持有的锁。而notify()和notifyAll()的作用,则是唤醒当前对象上的等待线程;notify()是唤醒单个线程,而notifyAll()是唤醒所有的线程。
Object类中关于等待/唤醒的API详细信息如下:
-
notify() — 唤醒在此对象监视器上等待的单个线程。
-
notifyAll() — 唤醒在此对象监视器上等待的所有线程。
-
wait() — 让当前线程处于“等待(阻塞)状态”,“直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法”,当前线程被唤醒(进入“就绪状态”)。
-
wait(long timeout) — 让当前线程处于“等待(阻塞)状态”,“直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者超过指定的时间量”,当前线程被唤醒(进入“就绪状态”)。
-
wait(long timeout, int nanos) — 让当前线程处于“等待(阻塞)状态”,“直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者其他某个线程中断当前线程,或者已超过某个实际时间量”,当前线程被唤醒(进入“就绪状态”)。
2.2 描述一个线程从启动到结束的状态变化过程
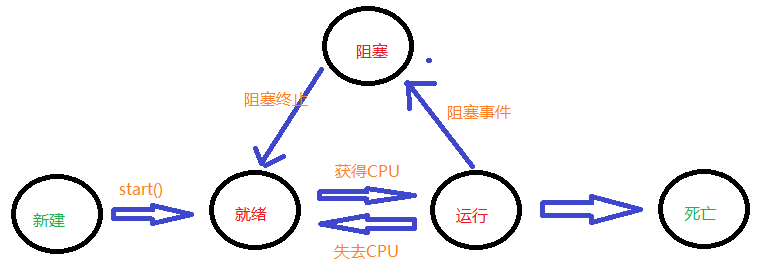
3. 线程控制
3.1 sleep()和wait()的区别
共同点: 他们都是在多线程的环境下,都可以在程序的调用处阻塞指定的毫秒数,并返回。
不同点:
- Thread.sleep(long)可以不在synchronized的块下调用,而且使用Thread.sleep()不会丢失当前线程对任何对象的同步锁(monitor);
- object.wait(long)必须在synchronized的块下来使用,调用了之后失去对object的monitor, 这样做的好处是它不影响其它的线程对object进行操作。
4. 共享数据
(七)网络编程
1. 计算机网络
2. IP地址和域名
3. 网络配置
4. Java与网络
5. Socket编程
(八)Java注解
1. Java注释概述
2. 内建注解
2.1 内建注解及其含义
@Override
- 重写
@Deprecated
- 已过时
@SuppressWarnings
- 抑制警告
相关属性值:
- deprecation: 使用了过时的程序元素
- unchecked: 执行了未检查的转换
- unused: 有程序元素未被使用
- fallthrough: switch程序块直接通往下一种情况而没有break;
- path: 在类路径中有不存在的路径
- serial: 在可序列化的类上缺少serialVersionUID定义
- finally: 任何finally子句都不能正常完成
- all: 所有情况
3. 自定义注解
3.1 示例
public @interface SqlProvider {
String value() default "delete from tableName";
String sql() default "";
}3.2 四大元注解
用于注解注解的注解
元数据
@Target
用于指定被修饰的注解能用于修饰哪些程序元素
相关属性值
- ElementType.AUNOTATION_TYPE: 注解类型声明
- ElementType.CONSTRUCTOR: 构造方法声明
- ElementType.FIELD: 字段声明(包括枚举变量)
- ElementType.LOCAL_VARIABLE: 局部变量声明
- ElementType.METHOD: 方法声明
- ElementType.PACKAGE: 包声明
- ElementType.PARAMETER: 参数声明
- ElementType.TYPE: 类, 接口(包括注解类型)或枚举声明
@Retention
用于指定被修饰的注解可以保留多长时间
@Documented
如果定义注解时使用了@Documented修饰, 则所有使用该注解修饰的程序元素的API文档都包含该注解说明
@Inherited
默认情况下, 父类的注解不被子类继承, 如果想要继承父类注解, 就必须使用@Inherited元注解
(九)软件测试与JUnit
1. JUnit初探
2. JUnit4应用
(十)扩展阅读(选学)
1. 排序算法
排序算法大体可分为两种:
一种是比较排序,时间复杂度O(nlogn) ~ O(n^2),主要有:冒泡排序,选择排序,插入排序,归并排序,堆排序,快速排序等。
另一种是非比较排序,时间复杂度可以达到O(n),主要有:计数排序,基数排序,桶排序等。
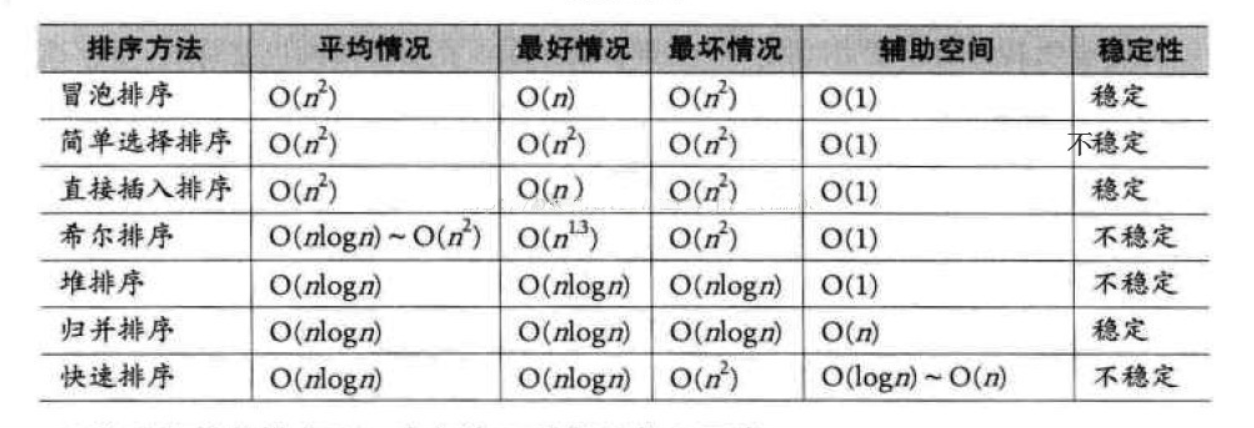
四个基础排序算法: 选择排序, 插入排序, 冒泡排序, 快速排序
- 选择排序:
首先,找到数组中最小的那个元素,其次,将它和数组的第一个元素交换位置(如果第一个元素就是最小元素那么它就和自己交换)。其次,在剩下的元素中找到最小的元素,将它与数组的第二个元素交换位置。如此往复,直到将整个数组排序。这种方法我们称之为选择排序
- 插入排序
过程简单描述:
(1)从数组第2个元素开始抽取元素。
(2)把它与左边第一个元素比较,如果左边第一个元素比它大,则继续与左边第二个元素比较下去,直到遇到不比它大的元素,然后插到这个元素的右边。
(3)继续选取第3,4,….n个元素,重复步骤 2 ,选择适当的位置插入。
- 冒泡排序
把第一个元素与第二个元素比较,如果第一个比第二个大,则交换他们的位置。接着继续比较第二个与第三个元素,如果第二个比第三个大,则交换他们的位置….
- 快速排序
从中轴元素那里开始把大的数组切割成两个小的数组(两个数组都不包含中轴元素),接着我们通过递归的方式,让中轴元素左边的数组和右边的数组也重复同样的操作,直到数组的大小为1,此时每个元素都处于有序的位置。